Data Dump Process
Description:
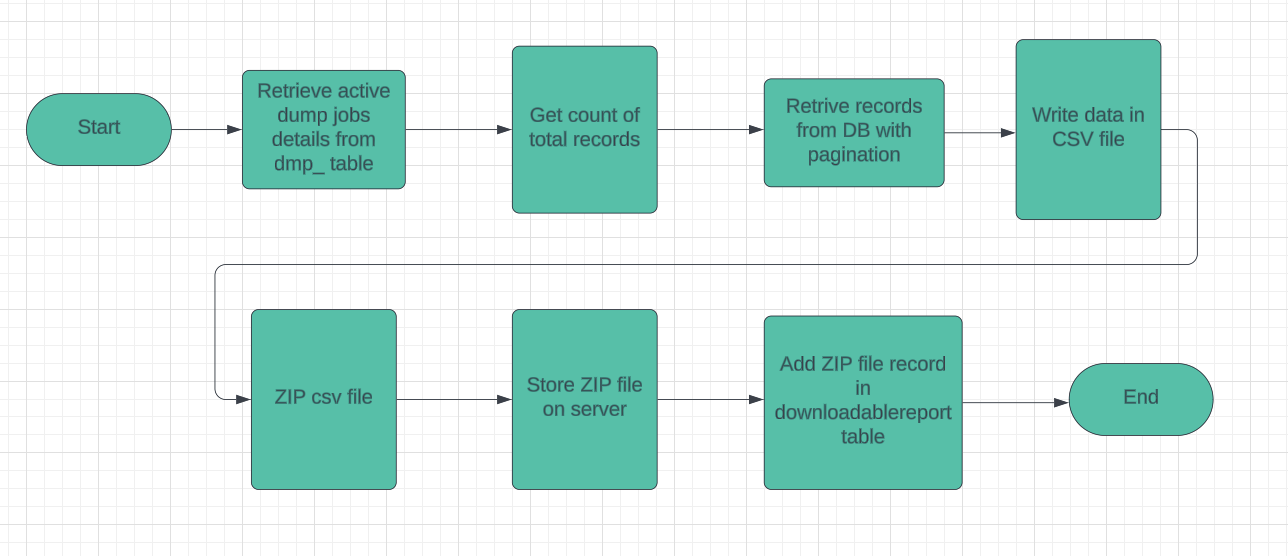
Data dump is a process to extract raw data from a database and write it down into a csv file to perform further analysis. It runs daily at morning 6.15 AM. Below are the detail breakdown of working of dump process;
-
Retrieve Active Dump Configurations
Executes a SQL query to fetch active dump configurations from the dmp_ table. These include procedure name, table name, file name prefix, page size, column projections, query string, and dump ID.
-
Count Total Rows to Process
Executes a COUNT(*) query to determine the total number of rows in the target table or a custom query. For specific cases like dmpId == 40 (mCCTs dumps), where the query lacks the DISTINCT keyword, the implementation doesn’t replace DISTINCT with COUNT for pagination purposes. In such cases, the count is fixed at 6,000,000.
-
Calculate Pagination
Computes the number of pages based on the total rows and page size.
-
Fetch Column Names
Retrieves column names for the target table or uses the projection string from the configuration.
-
Paginate and Generate CSV Files
Iterates through each page and performs the following steps:
- Define File Name: Constructs a unique file name using the page range and current date.
- Create ZIP File: Initializes a ZIP file and prepares it to hold the CSV file.
- Write Column Headers: Writes the column headers into the CSV.
- Fetch Data Rows: Executes a paginated SQL query using LIMIT to fetch rows for the current page.
- Write Data Rows to CSV: Write each data row into the CSV file. Clears the session periodically to manage memory.
- Handle Scrollable Query Errors: Logs any errors encountered during data retrieval and sends an email notification.
-
Close ZIP File
Completes the ZIP entry, flushes, and closes the ZIP file.
-
Store File Information in Database
Creates a DownloadableReport record with details like file name, path, type, and size. Saves the record in the database within a transaction.
Schedule:
| Job Name | Schedule |
|---|---|
| DataDumperJob.java | Every day at 06:15 AM |
Schema:
Below are the key tables used by DataDumperJob.java:
- dmp_
- downloadablereport
Dependencies:
None.
Process Flow: